T4 GPU + Llama: why your attention OOMs at 16K and the one-line fix
I was benchmarking Llama 3.2-1B inference on a free Google Colab T4 GPU, hoping to push the KV cache out to 16K context. The job OOMed at 4K. I needed long-context numbers to be meaningful.
Nothing in the error pointed at anything obviously wrong. The model loaded fine, a small input forward pass was fine, the memory usage looked normal until it didn’t. Somewhere between sequence length 2048 and 8192, GPU memory blew past the 16 GB ceiling.
The cause turned out to be a chain of three independently reasonable things:
- T4 is from 2018, with compute capability 7.5 (Turing). FlashAttention 2 and modern cuDNN attention paths require 8.0+ (Ampere). Hence both are unavailable.
-
PyTorch’s
scaled_dot_product_attenion(SDPA) is a dispatcher, not a single kernel. It picks one of four backends at runtime based on hardware, mask shape and a few other features. - With T4 + Llama’s GQA, SDPA falls through to math backend which materializes the full
[B, H, T, T]attention score matrix. At sequence length 16K, that matrix alone is 16GB. Goodbye memory.
The fix is a single kwarg in from_pretrained. This post walks through why the default path falls over, what the fix actually does, and roughly what it costs in compile time and memory overhead. If you’ve ever seen attention OOM on a T4, V100, or any pre-Ampere GPU, this is for you.
SDPA is a dispatcher, not a kernel
Pytorch’s scaled_dot_product_attention (SDPA) looks like a single function:
out = F.scaled_dot_product_attention(Q, K, V, attn_mask=mask, is_causal=True)
It’s not. Underneath, it’s a dispatcher that picks one of four implementation backends at call time:
- FlashAttention 2: A tiled, fused implementation. Never materializes the full attention score matrix in HBM, works on-chip in SRAM tiles. Hardware floor: Ampere (SM 8.0+).
- Memory-efficient SDPA: xformers-derived and similar tiling idea. Broader hardware support than FlashAttention 2 but stricter constraints size of Q, K and V heads.
- cuDNN attention: NVIDIA’s path. Recent past modes also need Ampere+.
-
Math backend: the textbook formulation. Compute
Q @ K^T, apply mask, softmax, multiply by V. Always available, always correct, materializes the entire[B, H, T, T]score matrix in memory.
The dispatcher tries them in order of most appropriate to least on the basis of various factors. Probably flash 2 first, math last. The first backend whose constraints are satisfied wins. The choice depends on compute capability, tensor dtype, mask shape, whether is_causal=True, and a handful of other flags.
The most important detail:
- The dispatcher is invisible. You wrote one function call. Whether you got the 4 GB-of-HBM math backend or a tiled fast kernel depends on configuration you can’t see at the API surface. There’s no warning when the dispatcher falls through.
If you want to see which backend was selected, PyTorch exposes context managers like torch.nn.attention.sdpa_kernel(...) to force or restrict backend, useful for debugging fall-through bugs. By default, you get whatever wins.
Why each fast backend fails on T4 + GQA
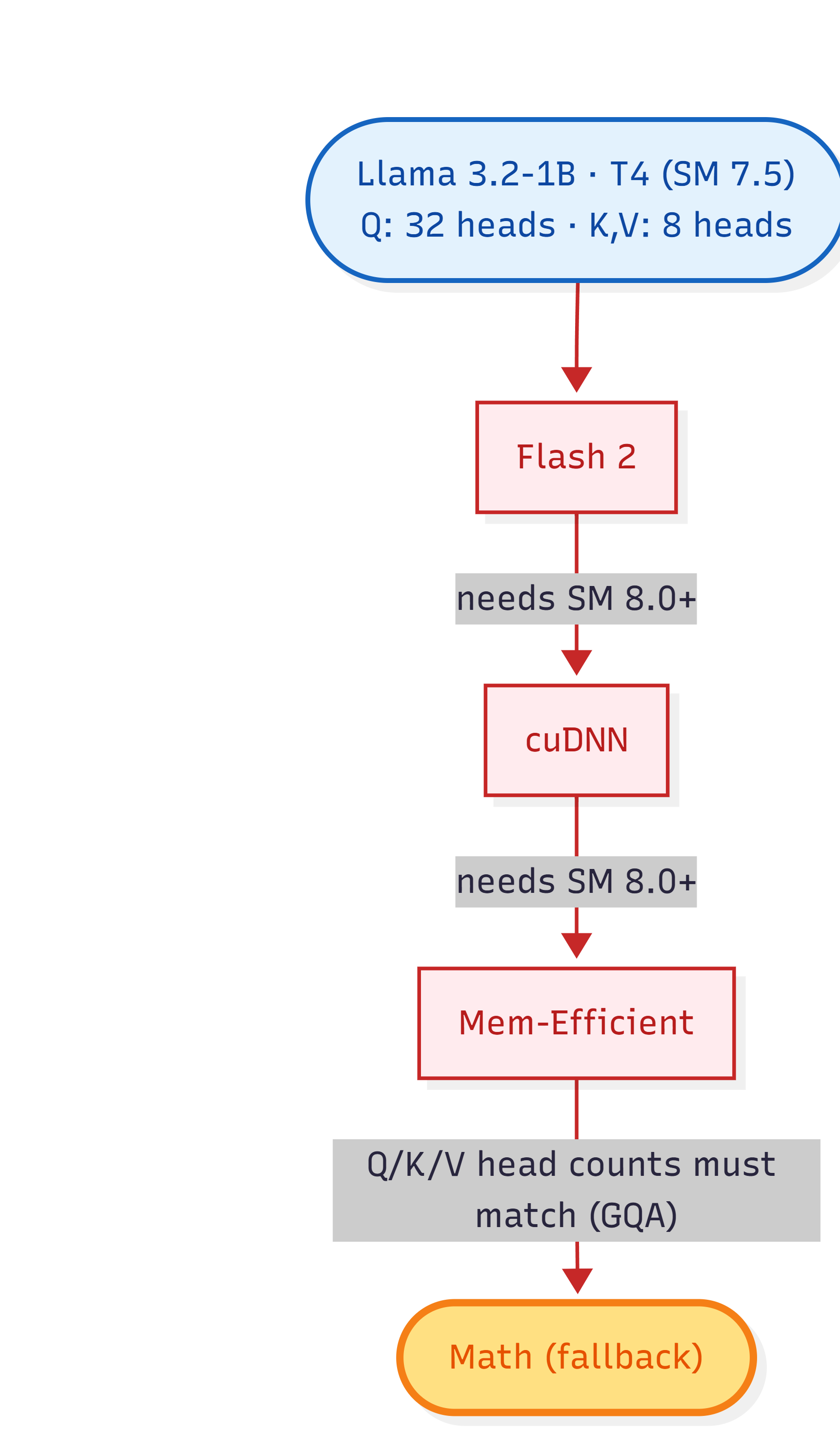
Three things have to be true for SDPA to land on a fast tiled kernel: the GPU must support the kernel’s compute primitives, the inputs must satisfy the kernel’s shape constraints, and the dtype must be compatible. T4 + Llama 3.2-1B miss differently per backend.
FlashAttention 2: hardware floor
FlashAttention 2 uses Ampere-specific warp-level matrix instructions. The CUDA kernel is hand-written for these and there’s no graceful degradation to Turing. PyTorch’s dispatcher checks compute_capability >= 8.0, T4 is 7.5, so Flash 2 is skipped immediately.
cuDNN attention: hardware floor
cuDNN 9.x’s fast attention API also targets Ampere+ tensor cores. Same hardware skip.
Memory-efficient SDPA: the GQA trap
This is the one that matters. The mem-efficient backend uses block-wise tiled softmax and runs fine on T4 architecturally.
But there’s a constraint I missed: the fused kernels require Q, K, V to have the same number of heads. Llama 3.2-1B uses GQA with 32 Q heads and 8 KV heads (a 4x ratio). transformers passes the tensors at their native shapes: Q is [1, 32, T, 64], K and V are [1, 8, T, 64]
The dispatcher catches the rejection and falls through to math.
This is why every modern open LLM hits this on Turing-era GPUs. Llama 3+, Mistral, Qwen 2+, Gemma 2 all use GQA. The fused kernel constraint disqualifies all of them. Pre-Ampere users running any post-2024 open model encounter this on the default SDPA path.
Math: what’s left
After Flash 2 and cuDNN are disqualified by hardware and mem-efficient is disqualified by GQA shape, the math backend is what’s left. Math always works. Next section explains what it costs.
What math backend costs
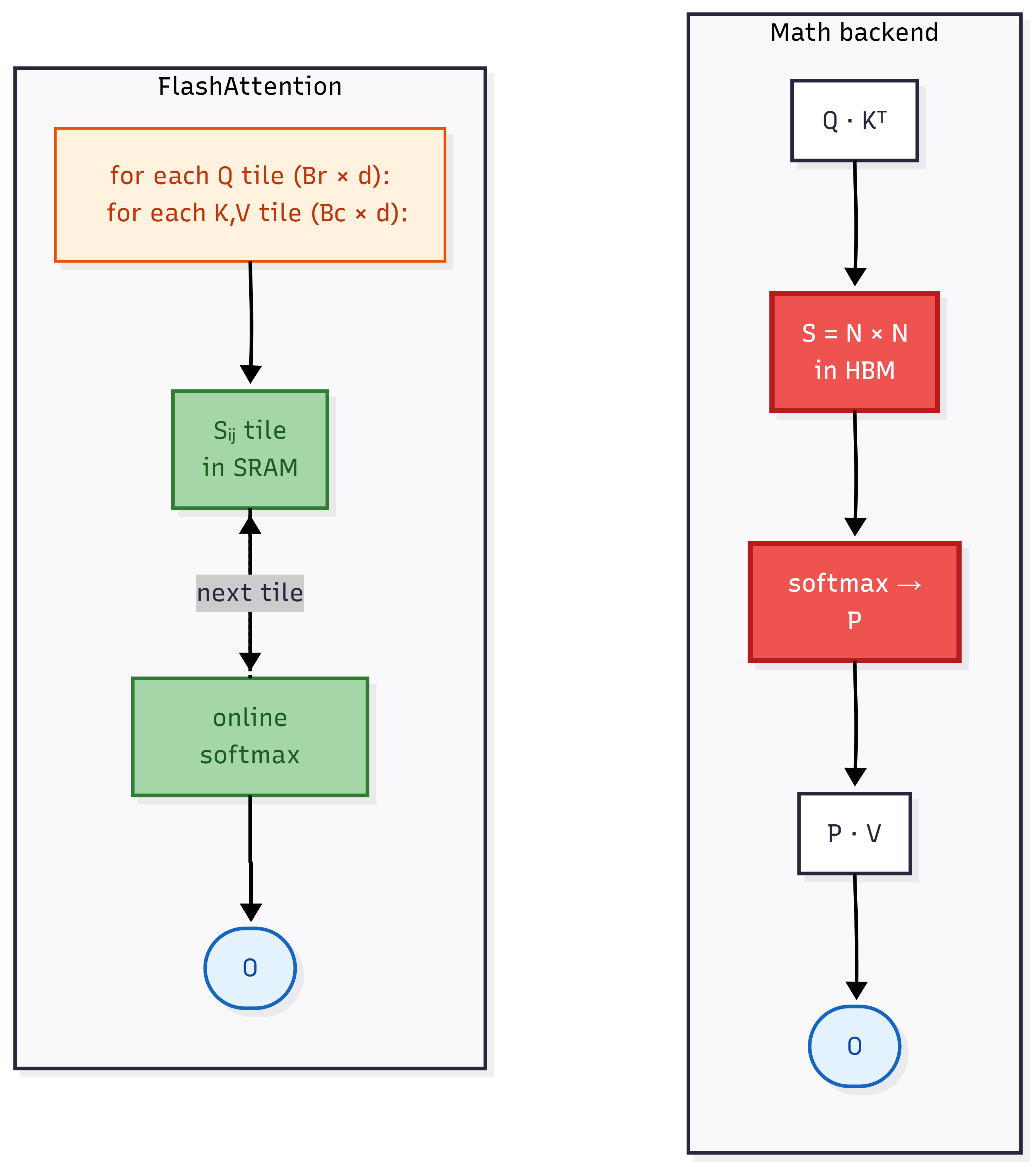
The math backend is the textbook formulation of attention, computed step by step:
-
Score matrix: $S = Q \cdot K^\top$ — shape
[B, H, T, T]. - Mask: fill masked positions with $-\infty$.
- Softmax: $P = \text{softmax}(S, \text{dim}=-1)$ (same shape as $S$).
-
Output: $O = P \cdot V$ — shape
[B, H, T, d].
Steps 1 and 3 each materialize a full [B, H, T, T] tensor in HBM. That’s the problem.
| Sequence length | Score matrix size (fp16) |
|---|---|
| 2K | 256 MiB |
| 4K | 1.0 GiB |
| 8K | 4.0 GiB |
| 16K | 16 GiB |
| 32K | 64 GiB |
The score tensor alone before the softmax, mask and matmul workspace, exceeds a T4’s 16 GB capacity at sequence length 16384.
At T=8192, my actual run threw the error:
OutOfMemoryError: CUDA out of memory. Tried to allocate 8.00 GiB.
GPU 0 has a total capacity of 14.56 GiB of which 3.43 GiB is free.
The 8 GiB allocation request is on the order of two score-matrix-sized tensors, consistent with the math kernel producing the score matrix and a separate softmax output.
This is what the math backend does by design. It’s correct. It’s also fundamentally $O(T^2)$ in HBM. We cannot support long contexts on a small GPU with this.
The contrast: tiled attention
The fast backends solve this by never materializing the full score matrix. They tile the computation: for each block of Q, iterate over blocks of K and V, compute the partial scores in on-chip SRAM, apply softmax incrementally using online softmax, and accumulate the output block by block.
The full [B, H, T, T] matrix is never materialized in HBM. Memory stays roughly $O(T)$ instead of $O(T^2)$.
This is what FlashAttention 2, memory-efficient SDPA, and FlexAttention all share. The differences are in which tile sizes, which hardware-specific instructions, and which input shape combinations each kernel handles. We’ve established that the first two don’t work here. The next section is what FlexAttention does differently.
Enter FlexAttention
FlexAttention is a PyTorch primitive added in version 2.5 (October 2024). It exposes attention as a Python function you can modify and compile, rather than as a fixed library kernel:
from torch.nn.attention.flex_attention import flex_attention
def causal(score, b, h, q_idx, kv_idx):
return torch.where(q_idx >= kv_idx, score, -float("inf"))
out = flex_attention(Q, K, V, score_mod=causal)
The score_mod function describes how to modify each entry of the score matrix. You write whatever attention pattern you need. Causal, sliding window, ALiBi, document boundary, anything as Python code. flex_attention then uses torch.compile to JIT a Triton kernel that fuses your modification into a tiled attention computation.
Three properties matter for our problem:
-
It generates a tiled kernel. The compiled Triton code computes attention block-by-block in on-chip SRAM, just like FlashAttention 2. It never materializes
[B, H, T, T]in HBM. Memory stays $O(T)$ instead of $O(T^2)$. - It works on Turing (SM 7.5). Triton supports T4, V100, and other pre-Ampere architectures. The generated kernel doesn’t depend on Ampere-specific tensor core instructions.
- It handles arbitrary num_heads ratios. GQA’s 32-Q-head / 8-KV-head mismatch — the constraint that disqualifies the memory-efficient SDPA is just a broadcast pattern in the Triton IR. K and V are virtually expanded inside the kernel.
The architectural insight is that FlexAttention bypasses the SDPA dispatcher entirely. When transformers is configured with attn_implementation="flex_attention", it swaps its SDPA-based attention layer for one that calls flex_attention directly with the appropriate score_mod for the model. None of the Flash 2 / cuDNN / mem-efficient / math fall-through chain runs at all, which means there’s no decision tree to lose to.
That’s the whole story: a kernel compiled for your specific GPU, handling GQA natively, never materializing the $T \times T$ score matrix. The next section is the actual code fix.
The fix in code
Pass attn_implementation="flex_attention" to from_pretrained:
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.2-1B",
torch_dtype=torch.float16,
attn_implementation="flex_attention", # this line
).cuda()
That’s it. transformers swaps its SDPA-based attention layer for one that calls flex_attention with a causal score_mod baked in for Llama. Forward passes go through Triton instead of the SDPA dispatcher.
Empirical effect on the same workload that OOMed before:
| Configuration | Peak GPU memory at T=8192 | Status |
|---|---|---|
attn_implementation="sdpa" (default) |
8 GiB allocation request fails | OOM |
attn_implementation="flex_attention" |
3.06 GiB total (weights + cache + workspace) | runs cleanly |
The forward pass works on the same input the math backend couldn’t fit. No other code changes. The rest of the model, KV cache wiring, and generation logic are identical. The attention kernel underneath is different, everything above it is the same.
Requirements
- PyTorch ≥ 2.5 for FlexAttention itself.
- transformers with the FlexAttention integration (recent versions are fine).
- Triton (auto-installed alongside modern PyTorch).
What FlexAttention costs
The dominant cost is compile time.
Compile time
The first forward pass with a given input shape triggers torch.compile to JIT a Triton kernel which typically takes 1-30 seconds depending on shape and Triton’s compile cache state. Subsequent forwards at the same shape reuse the cached kernel and run at full speed.
Different shapes recompile. A sweep across [512, 1K, 2K, 4K, 8K, 16K] sequence lengths triggers six compilations over the run. Standard mitigation: warm up before measuring. In my benchmark, n_warmup=3 per sequence length absorbs compile time before the timed iterations start.
If you skip warmup, your first measurement is dominated by compile and looks roughly 10–100x slower than steady state.
Memory overhead
FlexAttention’s compile cache and Triton runtime state contribute some memory overhead, but at the scale this benchmark runs at, it’s small enough that I can’t cleanly isolate it from activations. At T=512, peak memory is 2.36 GiB; model weights alone account for 2.30 GiB, leaving roughly 60 MiB for KV cache (16 MiB), prefill activations, and any FlexAttention state combined. The workspace is real but modest.
For the long-context use case FlexAttention is actually built for, any fixed overhead is dwarfed by what the math backend would have allocated for the score matrix.
A methodology note
torch.compile’s cache plus PyTorch’s caching allocator state accumulate across runs. After re-running the sweep multiple times in a single Colab session, peak memory readings drifted upward by hundreds of MiB even with torch.cuda.empty_cache() between runs. Restarting the Colab kernel between major experiments fixed it. Worth flagging if you’re chasing precise numbers.
Empirical numbers
Running the same Llama 3.2-1B forward pass on T4 with attn_implementation="flex_attention" engaged:
| Seq length | Peak memory | Prefill tok/s | Decode tok/s |
|---|---|---|---|
| 512 | 2.36 GiB | 4,647 | 41.6 |
| 1K | 2.40 GiB | 1,602 | 43.1 |
| 2K | 2.50 GiB | 942 | 28.7 |
| 4K | 2.69 GiB | 514 | 42.6 |
| 8K | 3.06 GiB | 269 | 43.2 |
| 16K | 3.82 GiB | 137 | 35.9 |
FP16 weights, batch size 1, single T4 (16 GB). Median of 10 timed runs after 3 warmup iterations. Full data and code at github.com/aswnrj/quantization-benchmark.
Main observation:
Memory stays bounded. Peak at 16K is 3.82 GiB. Almost 12 GiB of headroom on a 16 GB T4. Extrapolating linearly, FP16 KV cache hits the device ceiling around T=32K. The default SDPA path doesn’t reach 16K at all on this GPU, the math backend OOMs allocating the score matrix.
The headline finding: switching from attn_implementation="sdpa" (default) to attn_implementation="flex_attention" is the difference between running at all and OOMing, on any sequence length above ~4K with this model on this GPU.
Takeaway
The interaction is hardware, backend and model architecture. None of the three is unusual on its own; together, they conspire to OOM at moderate sequence length on consumer GPUs.
The lesson generalizes:
-
If you’re running a modern GQA LLM on any pre-Ampere GPU like T4 (Turing), V100 (Volta), P100 (Pascal), the default
attn_implementation="sdpa"path will OOM at moderate seq_len. Switch to FlexAttention. -
If you OOM in attention with no obvious cause, profile with
torch.profiler.profile()and look at kernel names.attention_mathorbmm-heavy entries mean the SDPA dispatcher fell through to math. -
If you’re benchmarking attention modifications, don’t assume
F.scaled_dot_product_attentionis using the kernel you think. Force a backend explicitly withtorch.nn.attention.sdpa_kernel(...)to verify.
The dispatcher is silent about its choices. That silence is the trap.
For the broader picture: PyTorch’s SDPA dispatcher was designed when most production training was on Ampere or newer. Pre-Ampere paths exist but are second-class citizens, particularly for the attention shapes that GQA and MQA architectures emit. FlexAttention sidesteps this by being a universal compile target. Triton runs everywhere PyTorch runs.
If you’re on Colab/Kaggle’s free tier (where T4 is still the default GPU) or working with older datacenter clusters (V100s remain common), this matters in practice. If you’ve migrated to A100/H100, none of this applies, the SDPA fast path is fine.
References
- Dao, T. (2023). FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning..
- Rabe, M. N., & Staats, C. (2021). Self-attention Does Not Need O(n²) Memory..
- Milakov, M., & Gimelshein, N. (2018). Online normalizer calculation for softmax..
- Haziza, D., et al. xFormers: A Modular and Hackable Transformer Modelling Library.
- Guessous, D., He, H., et al. (2024). FlexAttention: The Flexibility of PyTorch with the Performance of FlashAttention..
- Tillet, P., Kung, H. T., & Cox, D. (2019). Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations..