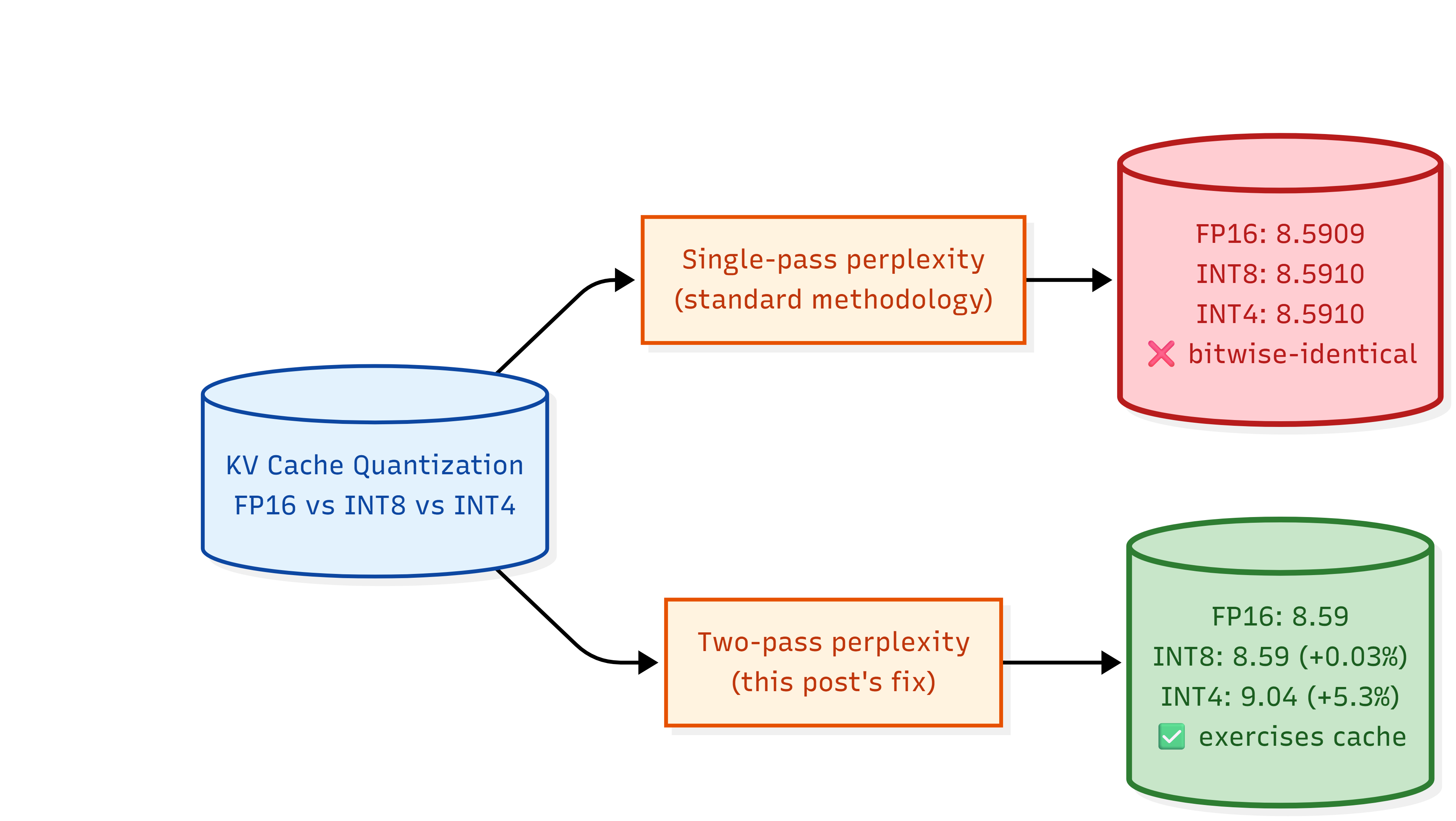
-
Why my INT4 and INT8 KV cache quantization gave bitwise-identical perplexity
When the standard sliding-window perplexity test produced identical numbers to fifteen decimals, the methodology was the bug, not the quantization.
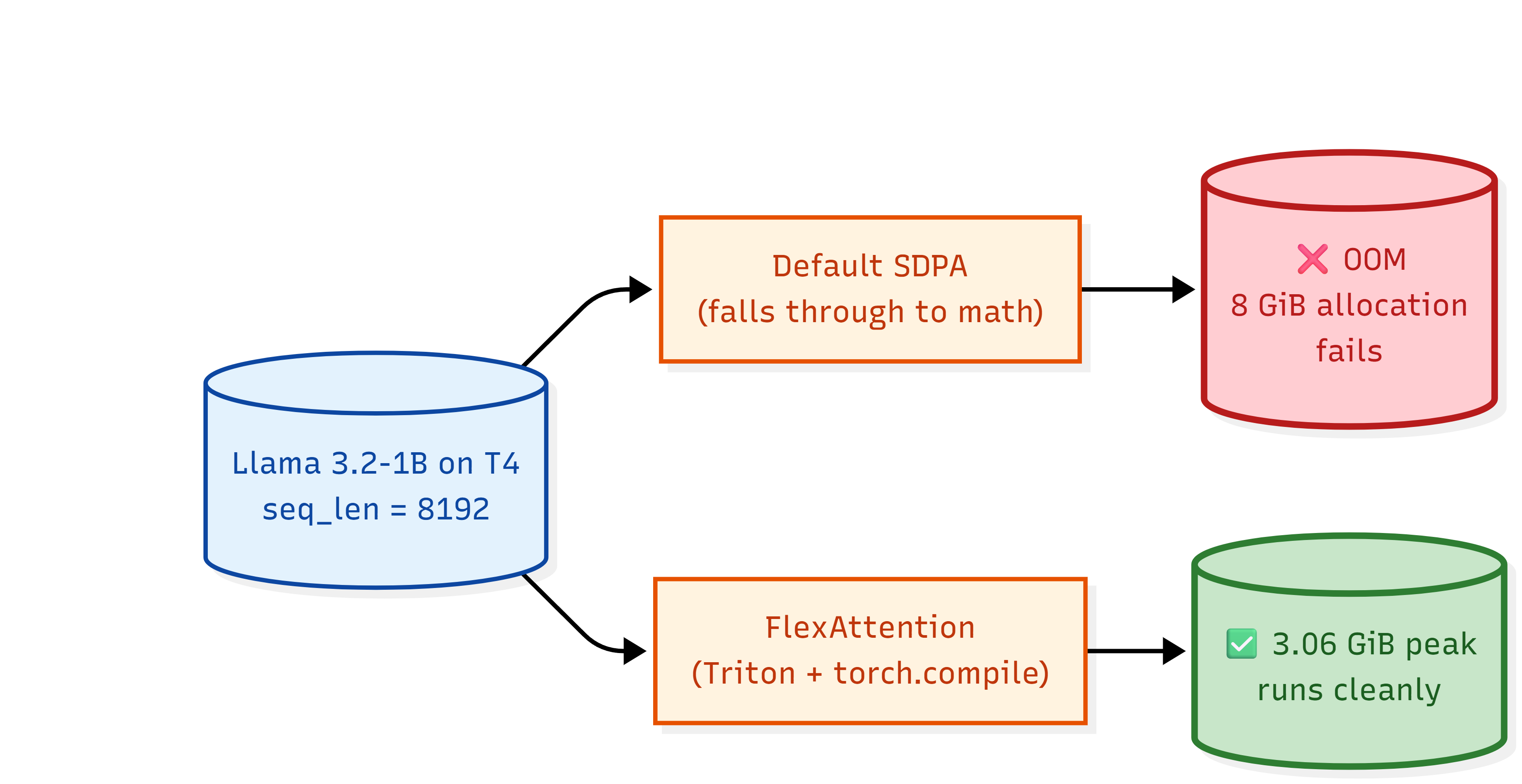
-
T4 GPU + Llama: why your attention OOMs at 16K and the one-line fix
A walk through why PyTorch's SDPA falls through to a memory-blowup path on Turing GPUs, and what FlexAttention does differently.